
GraphQL primer.
When we started evaluating GraphQL for a new project, it seemed to have as many detractors as fans.
The GraphQL tag line explains it as a query language for your api. But I’m not sure that really helps explain what it does, how it can help and whether it’s a good option. There’s also misunderstanding (and some misinformation) out there.
We ended up selecting it as our API platform, and have built up reasonable experience with the technology. We’ve learnt a lot of hard lessons along the way, which I’ll explain in this and a few upcoming posts.
What is it
It’s a query language or way to describe data.
Around this language are a range of libraries and tools - eg. servers, clients, services etc. These all combine to enable an API (or query system) which decouples services & allow us to ship value. Boom! Or so it says on the box.
We’ve been working heavily in the JS world (React, React Native, Node), so selected the defacto standard implementation of GraphQL by Apollo. Apollo builds the popular Apollo Client and Server libraries - which have over 300,000 downloads per week.
Apollo also offer paid services on top the platform. These services are totally optional though. You can use the open source libraries for free :-)
Why not just use REST
Strongly typed schema for free. That’s nearly enough of a reason right there. Having a contract is essential to building robust applications. GraphQL comes with a built in schema which contains all the operations (queries and mutations/updates), fields and data types.
Specify just the data you want in one operation. With REST, you typically have to fire off a number of calls, collate the data and then throw away the results you don’t need. With GraphQL you can specify just the data you need in one single call.
This does depend on your Schema design. With GraphQL you need to think about your API totally differently, not in single end points, but in graphs.
Where to start
We would’ve like these Principles to be around when we started with GraphQL. It could’ve prevented some wasted time, debate and mistakes. They’re a great starting point:
- Integrity: one graph, federated & tracked in a registry.
- Agility: build the graph up based on real needs, when needed. Just like evolutionary architecture!
- Operations: control access, layer and advanced logging.
Probably should read the official spec, or at least parts of it. It helps to understand what is GraphQL vs what is provided by libraries and third party add-ons.
Common objections
While GraphQL has now been around for some time (available publicly since 2015) and it’s usage is widespread, there are still plenty of detractors, misinformation and varied approaches.
One criticism we heard frequently is around losing control of your back-end. Front end engineers writing random inefficient queries. Will you loose control of data and back-end services?
To fuel that fire, there are tools like this which layer GraphQL directly on top of the database. They may be good for prototyping and some use cases, but the recommended approach is toward clear separation.
The power of GraphQL is highlighted when connecting a range of disparate services - which can be GraphQL, REST or really anything.
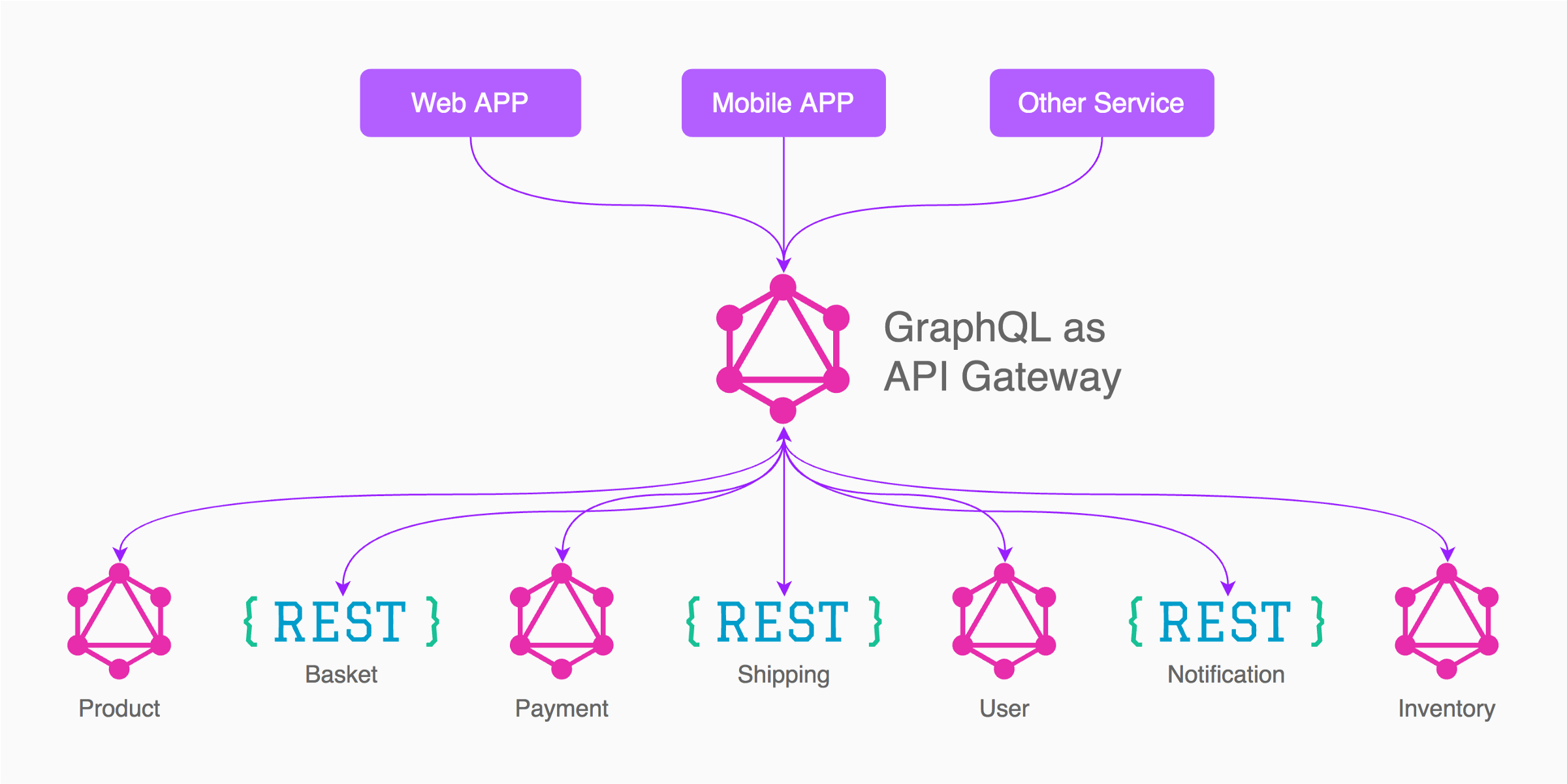 Image taken from this great article.
Image taken from this great article.
This separation allows GraphQL to be an API gateway. This solves a range of issues - and works in very well with micro-services. A single endpoint for clients but full control over data owners / teams / products on the back-end. This approach also enables greater control over data loading, caching, load balancing and error handling.
Next
Like every technology, GraphQL is not the perfect choice for every situation. If you have a very simple API that is unlikely to change, then REST is probably the best solution. If you have a larger, more complex API that will grow in size and complexity over time, then GraphQL might be the right choice.
In the next few posts, I’ll write up some of our lessons learnt.